
SkillUp AI社が提供しているPython入門講座の7日目を修了しました。
( 1日目, 2日目, 3日目, 4日目, 5日目, 6日目 )
Day7:データの前処理 について
データの前処理とは(復習)
機械学習でデータ解析をするための準備ですね。
機械学習による解析の精度を高めるためには、データの前処理が非常に大切であることは以前学びましたね。
実は、この講座全8回のうちDay1~Day7までが前処理です。それほど重要とのこと。
講座の内容
内容は以下です。
- 機械学習の前処理の基本的な考え方
- Titanicデータを使った前処理の演習
Day1~Day6までに学んだ内容の総まとめのようなものです。
機械学習の前処理の基本的な考え方
目的変数と説明変数
まずは、知っておくべき専門用語として「目的変数」と「説明変数」を知っておきましょう。
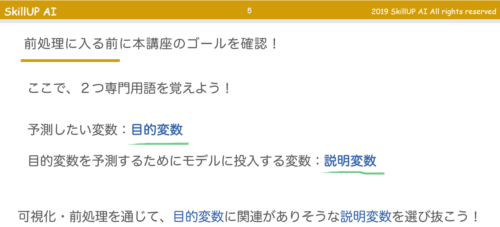
説明変数を選び抜く・精査するというのがデータの前処理目的ですね。
解析するデータを得られる Kaggle
今回の講習で解析する元データ(Titanicデータ)も、Kaggleというコミュニティから得ています。
Kaggleとは、世界中のデータサイエンスや機械学習に携わる人が参加するコミュニティです。データサイエンティストを目指す人は必見です。
データ予測のコンペティションでデータ予測のスコアが競われたり、他のユーザが構築した予測モデルのコードや説明も公開されています。学習にもってこいですね。
Titanicデータを使った前処理の演習
以下の流れで行いました。
- データの読み込み、データの概要確認
- データ可視化で前処理方針決定
- 前処理の実施
- 前処理を施したデータの保存
データの読み込み、概要確認
ここは特筆すべき点はありません。
プログラムでデータの読み込みと概要確認をするだけです。
データ可視化で前処理方針決定
ここで今までの講習で学んだ可視化ノウハウをフル活用します。
「欠損値」「外れ値」「グルーピング化すべきデータ」「不要と思われるデータ」などを確認するのですが、そのために箱ひげ図、ヒストグラム、ヒートマップといった可視化技術を駆使します。
前処理の実施
データを加工して意味のある特徴を作る、データ欠損値処理、カテゴライズ化、不要なデータ削除、文字列データを数値化といったことを行います。
以下「データを加工して意味のある特徴を作る」の一例です。
当講座では、タイタニック号沈没の生死の分析を例にしており、乗客の名前はそのままでは使えません。乗客の名前を不要なデータとして切り捨てるのではなく、名前に含まれる Mr. や Ms. や Doctor.といった文字に加工し意味のある特徴に加工して活用していました。
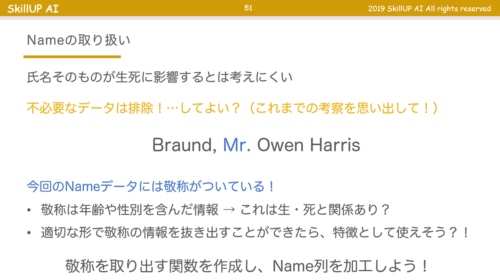
欠損値処理やカテゴライズ化なども行ったのですが、前処理はまさにノウハウと思える内容であり初心者はサクサクと思いつかないと思いましたね。
多くのデータを前処理して、経験を積んでいく他なさそうです。
前処理を施したデータの保存
前処理を完了したデータは、pickle形式(.pkl)で保存するのが基本のようです。
ここまでが、今回の講座の成果物ですね。お疲れさまでした(疲れた・・)。
Day7の感想
Day1~Day6の総復習といった内容で、知識を整理するには良い内容でした。
データサイエンティストの仕事が少しつかめてきたと思います。
最後のDay8で一通り終了です、頑張っていこう。


コメント