
SkillUp AI社が提供しているPython入門講座の最終日、8日目を修了しました。
( 1日目, 2日目, 3日目, 4日目, 5日目, 6日目, 7日目 )
Day8 機械学習モデルの構築と評価 について
与えられたデータから未来の予測結果を出力するモデルをつくること。
そして、そのモデルがどのくらいの精度であるかを評価すること。
大きくこの2点を学習しました。
機械学習の概要
機械学習には大きく分けて2つの機械学習のアプローチがあります。
①教師なし学習
②教師あり学習
教師なし学習は、「データだけを与えて、データの中の傾向をコンピュータに発見させる」アプローチとのこと。
教師あり学習は、「データとそれに対応する理想の出力を与えて、その間の関係性をコンピュータに理解させる」アプローチとのこと。
今回の講座では、教師あり学習のアプローチにてモデルを構築しました。
そして、教師あり学習の手法として「決定木」と「アンサンブル学習」についてざっくりと考え方の説明がありました。
なぜざっくりかというと、これら手法を実行するプログラミングモジュールが提供されているため中身のロジックを詳細に理解せずとも概要だけ知っておけば良いためです。
・・と私は理解しました。
-500x271.png)
学習データの分割
モデルに機械学習をさせる際に使う学習データ「train(トレーニング用)」を「tr_train(純粋なトレーニング用)」と「tr_test(トレーニング結果の評価用」に分ける方法・必要性について学びました。
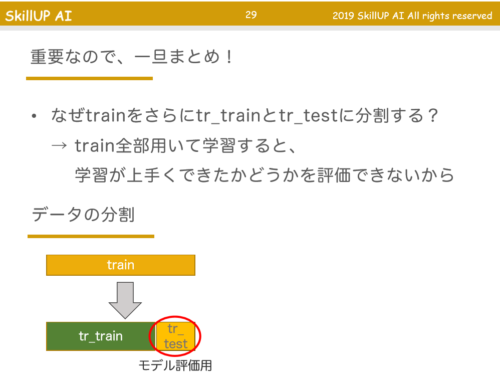
いやはや、この考え方は奥が深い。
学生の時に宿題に解かされたドリルとドリルのまとめテストのようなものか。
まとめテストだけは先生が預かっていて後でテストをさせられたがあれと同じ感じか。
モデルの構築
モデルを「作成」し、「学習」させ、結果を「予測」させる。
そしてモデルの「精度確認」をするところまでがモデル構築の一連の流れです。
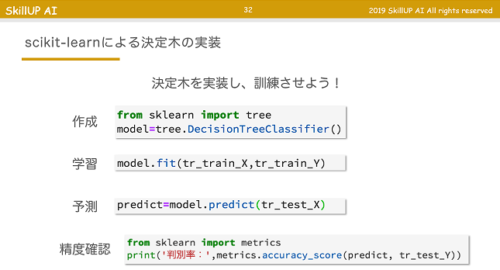
分割した学習データを引数に用いて、scikit-learnモジュールでモデルを構築します。
この辺はもう引数を与えるだけなので、見様見真似でコードを打つだけです。
モデルの検証
モデルが構築できたら、そのモデルを用いて、答えのないテストデータに対して予測をさせて結果を出力します。
出力結果は、KaggleのWebサイトに投稿することで成績が返ってくるそうです。これが評価ということでしょう。講座ではここまではしませんでしたが、流れは分かりました。
モデルの性能を高めるために、以下についても説明がありました。
1回の説明では絶対に覚えきれないので、こういった手法があるんだな~ くらいの理解度となりなした。
- K-分割交差検証(学習用データの分割手法)
- グリッドサーチ(モデルがもつパラメータのチューニング手法)
モデル構築 → 評価 → 手法を変える → モデル構築 → 評価 → …
こんなサイクルでモデルの性能を高めていくということですね。
Day8の感想
Day7までと比べて短かったですが、やろうとしていることは良く理解できました。
機械学習のモデルを作るためのアプローチや手法は多々あるようですので、今回学んだ内容は1つのケースです。本格的に機械学習を極めるためには、自分なりに色々な手法を試し、モデルを作り評価して経験を積んでいく必要があると思います。
今後のスキルアップのためには、Day7で紹介した Kaggleの活用がキーでしょうね。
世界中のデータサイエンスや機械学習に携わる人が参加するコミュニティ
講座の総学習時間は、約9時間でした。
このブログへのまとめ(頭の中整理)も含めると15時間くらいです。
今の会社の仕事と今回の学習は全く無関係ですが、機械学習に関して知識は確実に深められました。将来きっと何らかのアドバンテージとして還ってくるでしょう。


コメント